
Written by
Jonathan Taylor
Published on
Oct 6, 2025
I Built an LLM Visibility Tool; Here's What I Learned
I started work on my LLM visibility tool in February 2025. What began as a vibe coding project turned into a new service for my business—and an education in why sometimes the best business decision is not to build a business.
It's called Citebots. It's live, full-stack (as in, actually works), and I decided not to make a commercial version of it.
And I'm okay with that.
The New Marketing Channel Nobody's Measuring Yet
LLM visibility might be one of the most fascinating developments in recent history. For those unfamiliar: LLM visibility means getting your brand and content mentioned by tools like ChatGPT, Perplexity, Claude, and Gemini. It's a fresh channel for digital marketers—perhaps the most important new channel to arrive in a generation.
These tools already act as recommendation engines. Looking for a new camping trailer? ChatGPT will happily give recommendations, directions to the nearest dealership, and troubleshooting tips when you run into issues. True story: I bought my family a tent trailer with ChatGPT acting as presales consultant. Major purchases now warrant a check-in with your neighborhood friendly LLM.
Brands have caught on. ChatGPT ranks among the most visited websites in the world, and its ecommerce capabilities are just around the corner. We're entering the era of consumption copilots.
This isn't just retail. My work focuses exclusively on B2B, and LLMs are fast becoming a steady referral source. Marketing is about being where your buyers are. LLMs give an extra advantage—they account for the buyer's context and requirements before making recommendations.
Building the Tracker
LLM visibility tracking for brand mentions and citations
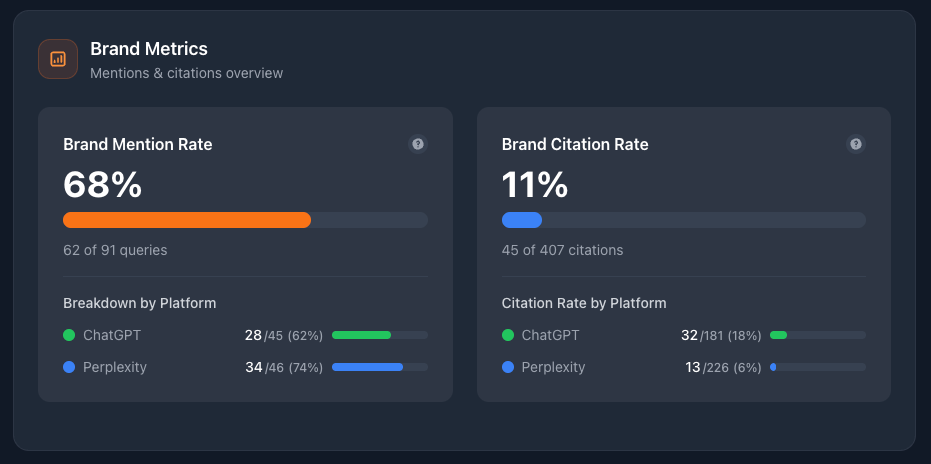
Anything this important requires metrics. Digital marketing is nothing if not data-driven.
February 2025: LLM visibility questions had gone from quiet murmur to thunderous conversation on LinkedIn. Point solutions were scant, metrics out of reach. In the intervening six months, the space has exploded with tools accounting for tens of millions in investment.
My experience building Explain Like Sci-Fi had familiarized me with the Perplexity API and the limitations of using LLMs for information sources. A sad artifact of my content assembly for ELISIFI: many links retrieved from research queries returned 4XX errors.
From this experience, I realized I could build an LLM tracker that programmatically calls LLM APIs, parses responses, and tracks metrics. Let me share some architectural decisions in hopes of demystifying this technology.
Query Fanning: Solving the Scale Problem
Query fanning in LLM application
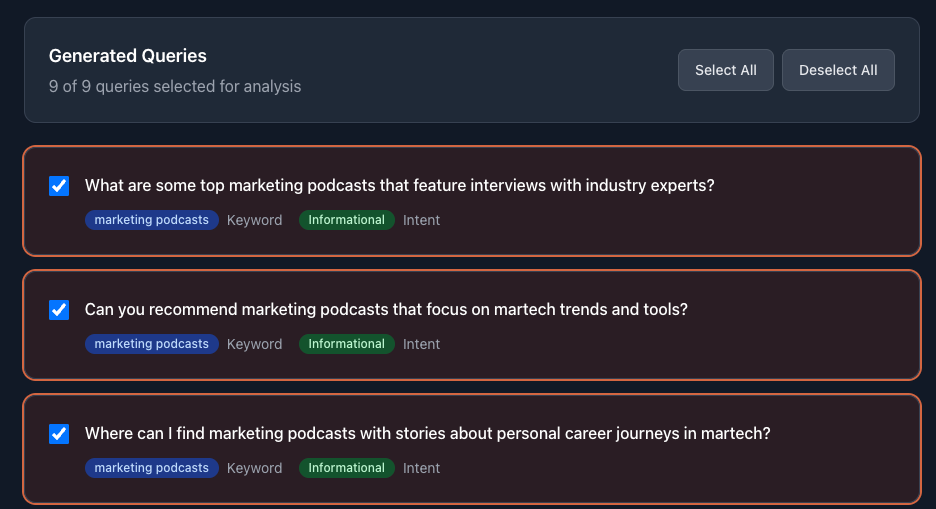
The first question when starting out: what queries should you track?
Sure, you can rattle off a dozen queries quickly. But how about 100? Can you account for various personas, use cases, competitors, and query types? Like keyword visibility, the value lies in finding the diamond in the rough.
I realized early I couldn't manually select queries for analysis. I could supply key ones, but to get meaningful data, I needed to test hundreds of queries.
I developed a query fanning algorithm that takes keywords or phrases and transforms them into natural language queries for the LLMs. During generation, I can select query types to generate and which platforms to test. A single keyword can create as many as five queries. Then I vet and evaluate individual queries, scanning through them for relevance.
Brand Knowledge Files: Adding Context
Knowledge files created for LLM visibility tracking
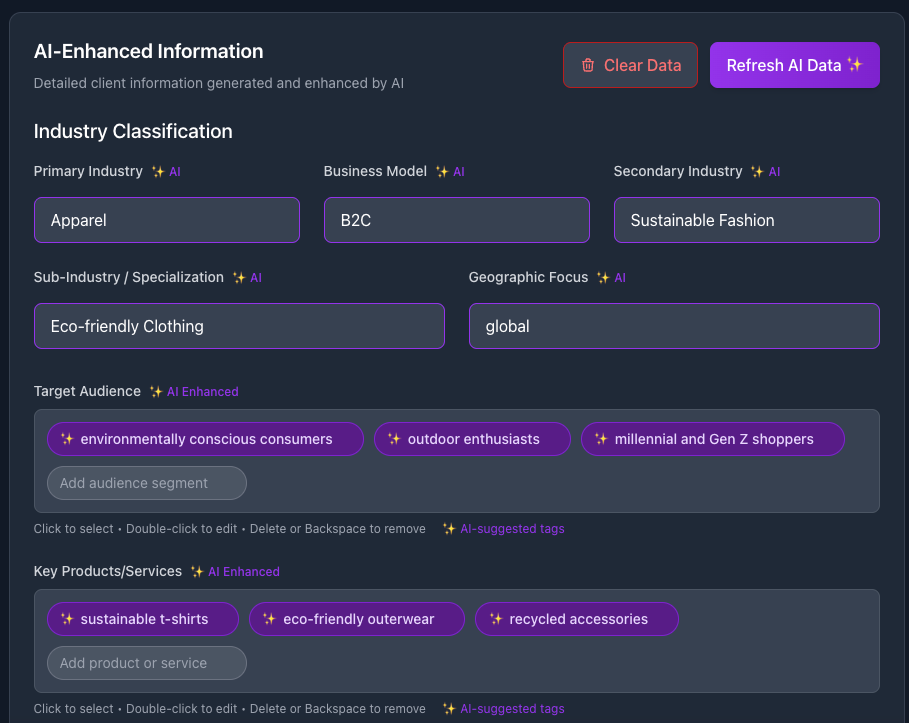
Once I solved query fanning, something was still missing. The queries felt generic and wooden. I needed to augment the process with brand information—allowing it to self-identify personas, tweak language for industry relevance (not asking enterprise questions for SMB-focused companies), and understand competitors.
This required creating a knowledge set per client. I implemented this through client creation, using a combination of ChatGPT, Perplexity, and web scraping to compile company profiles with standard information.
Brand knowledge files immediately leveled up my queries and play a role at the analysis stage. Like a micro-AI agent preloaded with context, able to sense (some) nuance.
Over-Engineering the Page Crawling
Citation tracking in LLM visibility
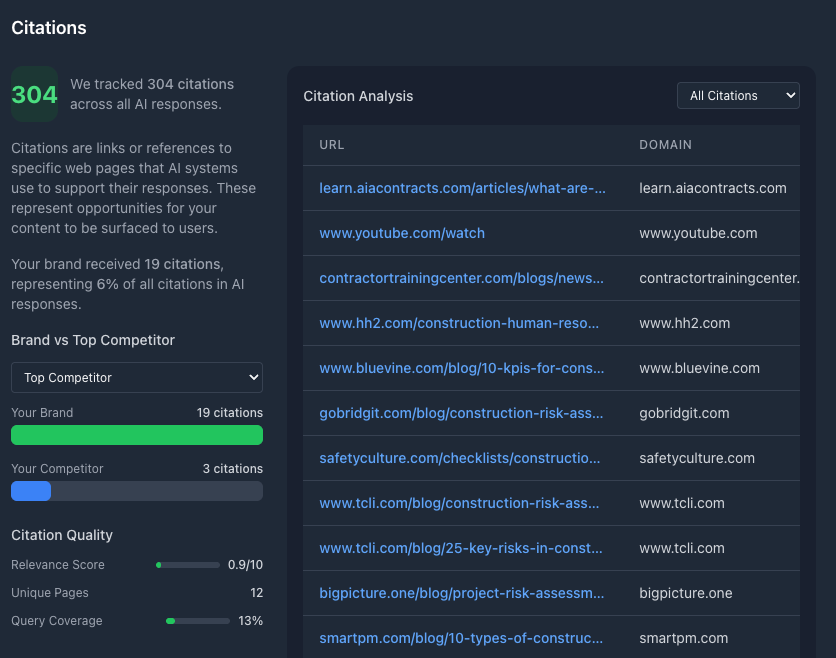
The biggest flaw in my current Citebots iteration? I also crawl each page returned by LLMs. I get Perplexity and ChatGPT to return their cited pages (hence the name Citebots), then use a web scraper to crawl each one.
I extract about 100 data points from each page. I over-engineered the hell out of this.
I collect data like:
- On-page SEO and HTML: Number of headings, images, title tags, meta descriptions, usage of tables, lists
- Technical SEO: ARIA and Schema presence
- Web speed: Google Lighthouse scores
- Moz Rank: Domain authority, page authority, propensity to link
- AI-generated insights: Content analysis, query-response match scores, EEAT signals, content recommendations
It's an awesome amount of data. It's also extraneous, largely confirming what we already knew or guessed. Yes, Schema/Structured Data appears in 70% of cited sources in my dataset. Yes, domain authority seems to factor in. Yes, pages matching user queries are more likely to be cited.
Page-level stats are valuable, but they're expensive to extract, increase analysis time, and yield only moderate insights in the tracking context. The real use case for page crawling with LLM visibility? Creating content, doing research, or running gap analyses.
Query Data: The Real Gold
Query data in LLM visibility
The query-response data is the focal point. Two driving questions for LLM visibility:
- How do I appear in LLMs compared to competitors?
- Is my product being recommended by LLMs?

Brand monitoring and competitive intelligence in LLM visibility
For proper competitor tracking, I needed companion knowledge files for each brand. These store competitor information, allowing us to programmatically single out competitor mentions in a sea of responses. We track direct competitor and brand mentions, plus any cited pages.
Queries become a way to understand what sources LLMs reference when you come up. Finding review sites that mention you could be the push to update them with latest features and fresh reviews.
I run brand sentiment analysis on each response to see if clients are mentioned positively or negatively.
Product mentions matter. I've uncovered more than a few disparities between what LLMs say and what brands actually do. Or, more vexing, disagreement on product names. For instance, a company that rebranded their product to just their brand name after years of using a multi-word product name.
LLM training data conflicts with what they find via web search. As models like GPT-5 seek to augment responses by dynamically choosing whether to perform web searches, an opportunity opens to clean up entities and ensure naming conventions are consistent.
We're currently using Screaming Frog to run custom extractions and replace all mentions of previous product names with new ones.
Answering the "Now What" Question
Once I got LLM visibility working in Citebots, I started presenting reports to clients. Big win—it showed I was proactively addressing this new marketing channel. It also saved them from acquiring expensive tools. Price tags on many solutions are clearly enterprise-focused.
LLM visibility remains somewhat speculative. With Citebots in hand, my clients could put principles into practice and determine viability themselves.
What intrigued me more than metrics was the recurring "now what" question.
The answer: experiment.
I've done two things that work:
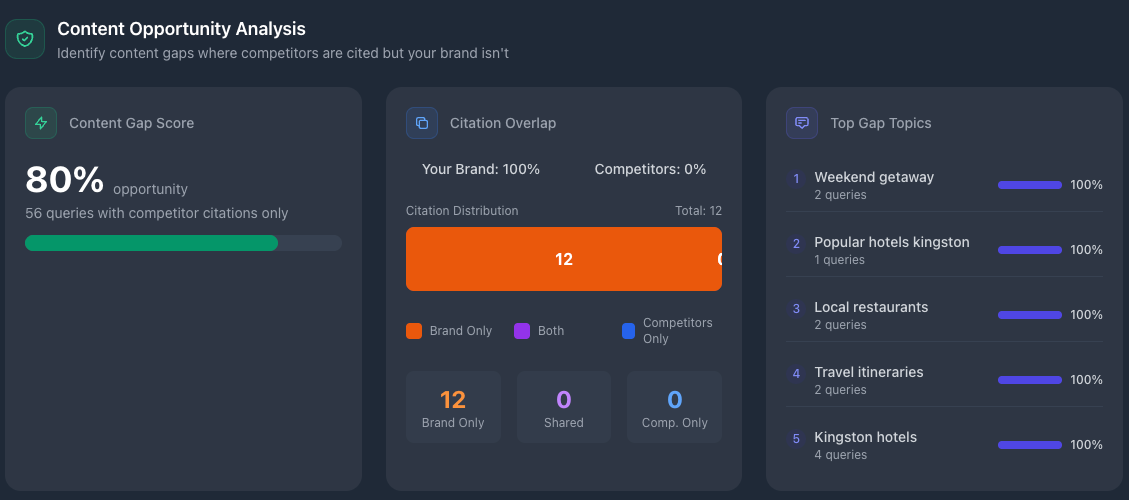
First, I target queries and patterns where competitors get mentioned but my brand doesn't. This feels like the natural starting point, particularly for comparison content. Whether raising awareness about review sites and social recommendations or directly writing competitive content, this strategy consistently delivers results. One client saw a 40% increase in LLM mentions after we identified and filled three specific content gaps their competitors owned.
Second, I now use LLM visibility for each piece of content I write. I batch content and generate query lists for each piece. Then I run queries to see where we play well and where we need improvement. It also surfaces all cited content, so I can see what LLMs prefer and identify competitive content gaps.
Why I Didn't Make Citebots Commercial
Personalized LLM visibility tool
Am I kicking myself for not making Citebots a commercial application? Surprisingly, no.
What I built is commercial grade—validated by clients and dozens of friends who've used it. The data I collect is unique, valuable, and above all, exhaustive.
Despite positive feedback and confidence in product quality, I opted not to launch.
Candidly, the work involved in maintaining an application like this is too daunting for a solo developer. Take the launch of a new ChatGPT version, like GPT-5. Right away I'd need to add those capabilities, accounting for different API calls. Sometimes new API versions require significantly retooling scripts.
I talk about this in my disposable software article, but I genuinely enjoy a certain detachment from the things I build. Sometimes what we build becomes an anchor. LLM visibility is a fascinating space, and I'm glad I've got my own tool to learn, experiment, and develop. But going commercial meant going all-in on this single discipline.
LLM optimization will be a mainstay of digital marketing. It's a core part of my services. But it's one piece of a larger puzzle.
Ultimately, I'm a practitioner. I want to use these tools to do things—to experiment and see what different elements can achieve. It's why I got into marketing. Building tools should serve that goal, not become the goal itself.
I'll admit there were technical challenges that, while solvable, helped me realize I didn't want to manage a growing user base. The operational overhead would transform me from marketer who codes to developer who markets. That's not the business I want to run.
Instead, I opted for a value-add for my clients and a tool I use daily. Citebots does exactly what I need it to do, evolves when I need it to evolve, and stays out of my way the rest of the time. Sometimes that's the perfect product-market fit—when the market is just you and your clients.


